1x patty of Steak-EZE Thinly Sliced and Shaped Sirloin Steak Strips, Frozen
4 x eggs
1 x 10″ diameter tortillas (the whole wheat carb balance kind has 110 calories, the flour kind has 210 calories)
Shredded cheddar cheese
Olive oil
Instructions
Warm up the tortilla in a 10″ pan on low heat
Put 2 tbsp of olive oil in a small 8″ pan on medium-high heat
Add the steak patty and cook patty for 2 minutes
Flip patty and cook for another 2 minutes
Using a heat-resistant silicon spatula, break the patty into small strips.
Transfer steak strips to a strainer over a small bowl and press to squeeze juices out. This will limit how much juice will leak through the bottom of the burrito and make a mess.
Flip the tortilla and cook the eggs. I prefer to scramble them.
Turn off the heat to the eggs before they’re done because they will continue to cook on their own
Sprinkle some shredded cheese on the eggs, add the steak, and mix
Transfer the mixture to the tortilla
Let the mixture cool a bit while washing the dishes
Cherry-picking individual commits to merge them from one git branch to another is a very common practice. For me, I usually cherry-pick one or more commits from a develop branch to a master / main branch. The problem, however, is when I need to cherry-pick multiple commits made over a long period of time, like one month. Most git clients don’t make it easy to filter commits by keyword, and if they do, then they don’t let you easily select all filtered commits. So, back to the command line it is.
This post will describe one way to easily find all commits matching one or more keywords and extract their commit IDs on one line so you can quickly run the git cherry-pick command.
Step 1: Find and review filtered commits
We usually prefix our commit messages with an identifier so we can filter them amongst many other commits. For example, all commits to related to one project may have a commit message prefix of “LP:8929” where, in this case, “LP” stands for Landing Page. Sometimes, we might accidentally use an equal sign (=) instead of a colon (:). So, we’ll have one or more keywords to search commit messages when we filter all commits.
Furthermore, we usually cherry-pick commits from a develop branch to the master branch while we’re on master. The following command does the following:
Command
Description
git log
get the git log
master..develop
as we’re on the master branch, get the log from the develop branch
--oneline
format the output in one line (short format)
--grep='LP:8929' --grep='LP=8929‘
filter results to only results containing either ‘LP:8929’ or ‘LP=8929’
-i
do a case-insensitive search
git log master..develop --oneline --grep='LP:8929' --grep='LP=8929' -i
48b1cbcef51 LP:8929 - Fixed images path by using imagekit variable
8efa19678b3 LP:8929 - Fixed text alignment
3ab0954c725 LP:8929 - Updated banner and VS page on the landing page
bba58a1c5eb LP:8929 - Updated main heading of features section
fb56da3b134 LP:8929 - Updated content and created carousel as per the requirement
c7c6d50fbdb LP:8929 - Updated styling of the page
bc8a7fc38a1 LP:8929 - Updated icons of the comparison section
9a90ccb91ad LP:8929 - Updated text styling
a3bc0baf65f LP:8929 - Updated headshots and styling of the page
13977d2eb12 LP:8929 - Updated content as per the doc
7e589debba8 LP:8929 - First Pass: Created Landing page of Tenable v Qualys competitive page
Now that we have our list of commits, we need to review them to make sure they are correct. In our case, we primarily want to make sure the keywords are at the beginning of the commit message since that’s our commit message format.
Step 2: Extract commit IDs
If our list of commits is correct, then we need to extract the commit IDs. However, the git cherry-pick command requires the list of commit IDs to be in chronological order. By default, the git log output is in reverse chronological order. Here’s the updated command with some modifications.
Command
Description
--reverse
Reverse the git log output to chronological order
awk '{print $1}'
Extract only the text output in the first column (commit IDs)
Now that we have our list of commit IDs in the correct order, we can copy it, type “git cherry-pick” and paste the list to create a command like the following.
Svelte is a JavaScript framework similar to React, Vue, etc, but with some fundamental differences that I think make it better. It’s also much more intuitive to understand as the web component structure of the code is dead simple. When building an app using Svelte, you’re encouraged to use Sveltekit, the official Svelte application framework. But, if you just want a simple frontend-only site/app, then you can just use Svelte (without Kit). In doing so, you can then easily take the built CSS and JS files and include them in any existing web page. Then, you just add a simple div
<div id="app"></div>
in your existing HTML file where you want the app go to.
Here’s an example.
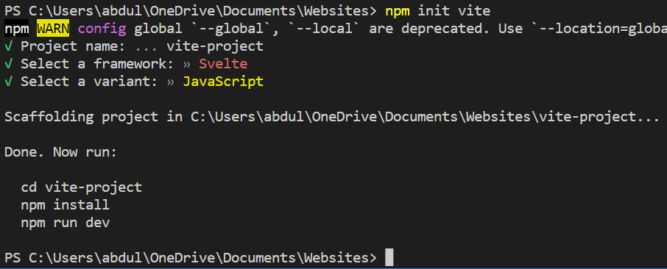
Create a Vite Project
Vite is a front-end build tool and dev server. It includes Rollup to bundle and optimize assets. Run npm init vite and follow the prompts. As you can see in the screenshot below, I chose the default project name of “vite-project”.
This will create a folder named after your project and create some files and folders within it.
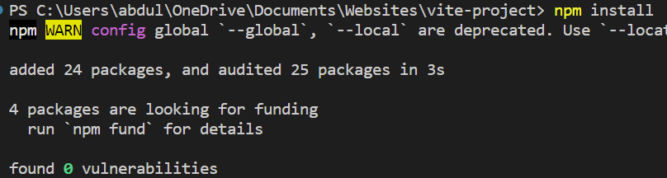
Then, as the instructions say, run the commands
cd vite-project npm install npm run dev
npm install will download the node packages specified in the package.json file into the node_modules folder.
Start Dev Server
npm run dev will launch a dev server. Running the dev script starts a program called Vite. Vite’s job is to take your application’s source files, pass them to other programs (including Svelte, in our case) and convert them into the code that will actually run when you open the application in a browser.
If you go to the local URL http://127.0.0.1:5173/, you will see the starter Svelte app that was created automatically.
The app includes a simple interactive counter. When you click the button, the counter increments.
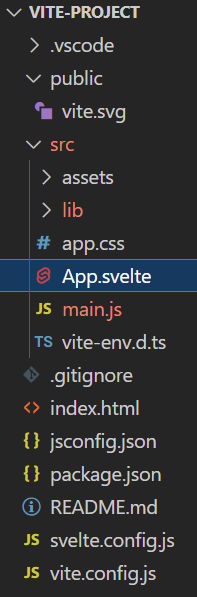
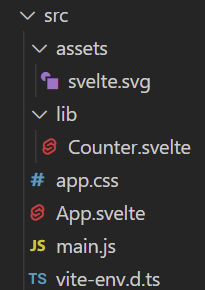
src Folder
If you look at the src folder, you’ll see a few files:
The assets folder contains static assets, like images
The lib folder contains Svelte components. In this case, there’s the counter component.
app.css is a global CSS file for the entire app
App.svelte is your main app code. In this case, it imports the svelte.svg logo and the Counter component.
<script>
import svelteLogo from './assets/svelte.svg'
import Counter from './lib/Counter.svelte'
</script>
main.js is the main JavaScript file. It loads your app’s CSS (app.css) and your app’s main code (App.svelte). It will also load the app in the HTML element with ID app.
import './app.css'
import App from './App.svelte'
const app = new App({
target: document.getElementById('app'),
})
export default app
Build the App for Production
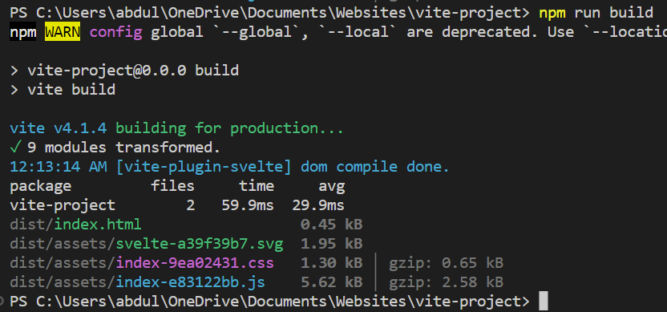
When you’re done developing your app (creating components, etc), you can run a build. This will bundle all CSS and JS files into a single CSS and JS file, optimize the bundle (e.g. minify it), and output the production files in the dist (distribution) folder. Run a build with the following command.
npm run build
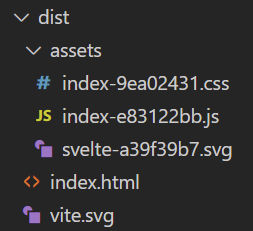
You’ll see a dist folder created. In this case, with the following files:
If you open index.html, you’ll see it references the two bundled CSS and JS files along with a div element with ID app where the app will be injected.
There are many different types of website content management systems. This post will explain the different types and include some examples.
No-Code CMS
A no-code CMS is one where the entire website is managed by the CMS. For example, with webflow, all changes to your website must be done in the CMS using a WYSIWYG. You can only edit the HTML of the code widget. All other changes must be done using the UI. If you want to edit the source code of the entire site, you must export the entire site. But, you can’t import any changes you made from the export.
A database-driven CMS is one that stores some or all data in a database. For example, WordPress is one such CMS. Web pages and blog post content are stored in a database (usually mySQL). Unlike webflow, however, you can edit the source code of the web page templates. WordPress has a built-in versioning system, so you can see a history of changes made to a page.
A headless CMS is one that stores data remotely. Data is integrated with your website using an API. For example, Contentful is one such CMS. You can create custom content models in Contentful. Your website will need to access the data at a particular URL that returns JSON data. Your website will then need to consume that JSON data to process it to show it on a web page, e.g. by using a template engine. Data in Contentful is likely stored in a database.
A git-based CMS stores data in git version control. Unlike many of the other CMSs, this CMS connects to your git repository as a web developer does. It then shows an interface that allows content editors to make edits to files in the repo. CloudCannon is one such CMS. With CloudCannon, web developers can add the class “editable” to HTML tags with a page’s source code. Then, the content of those tags will be the only elements that content editors can edit.
Websites that are built using a static site generator (SSG) often include front matter. Frontmatter can come in different formats. One popular format is YAML. You can have YAML at the beginning of a page’s source code. Or, you can have a separate, standalone .yaml file. YAML contains contain name-value pairs, so they basically represent data. Netlify CMS is one type of CMS that supports editing YAML. It also supports editing pages like blog posts. However, unlike WordPress, where editors can add blocks of content to a page’s body, Netlify CMS requires the blocks of content to be predetermined upfront. So, for a blog post using Netlify CMS, editors can only use one widget to entire the entire body of the page. That widget is a rich text or markdown editor.
The CMSs above can be categorized as CMSs that support structured and unstructured data. CloudCannon supports unstructured data because you can let editors edit specific elements of a complex page by marking those elements as “editable”. YAML and database-backed CMSs support structured data because there is a clear name/value mapping.
My Preference
Since WordPress is the most popular CMS and it allows editors to add blocks of different types of content to the body of a page, I think it’s worth using. However, I don’t like that WordPress keeps data in a database and relies on PHP to build pages before serving them. Also, not all pages need to be edited by non-technical people. In fact, most pages will still be edited by developers who need full access to the source code. To accommodate the needs of both developers and non-developers, I would use GitHub to version all code changes and I would use a static site generator like Eleventy that is integrated with WordPress using the WordPress API. When a WordPress editor saves or publishes a page, WordPress can trigger a save_post() action with a callback function that calls a URL, e.g. a PHP script on Heroku at myapi.com/?postid=123.
function call_commit_script( $post_id ) {
$remote_url = 'https://www.myapi.com/?postid='.$post_id;
$access_token = '3&^&2lhl3@#lsjk756'; //some secret password
$args = array(
'headers' => array(
'Authorization' => 'Bearer ' . $access_token,
),
);
$response = wp_remote_get( $remote_url, $args );
if ( is_array( $response ) && ! is_wp_error( $response ) ) {
$headers = $response['headers']; // array of http header lines
$body = $response['body']; // use the content
}
$post_title = get_the_title( $post_id );
$post_url = get_permalink( $post_id );
$subject = 'A post has been updated';
$message = "A post/page has been updated:\n\n";
$message .= $post_title . ": " . $post_url\n\n$body;
// Send email to admin.
wp_mail( '[email protected]', $subject, $message );
}
add_action( 'save_post', 'call_commit_script' );
The PHP script on Heroku could then
verify the Authorization Bearer header contains the predetermined access token value, e.g. 3&^&2lhl3@#lsjk756. If it doesn’t, then the request didn’t come from an authorized origin and should be rejected.
pull any latest changes from GitHub
call the WordPress API to get the page content in JSON format, e.g. https://www.mywordpresssite.com/wp-json/wp/v2/pages/123
commit the JSON data to GitHub
use the static site generator to build the page using the JSON data as the data source
Note: the PHP script on Heroku, e.g. https://www.myapi.com/?postid=’.$post_id, must be secured by SSL/TLS to encrypt the URL and headers so that attackers can’t see the authorization header value.
For allowing non-technical people to
edit simple YAML files or frontmatter, I’d use Netlify CMS.
edit complex, structured data, I’d use Contentful.
edit specific, unstructured content, I’d use CloudCannon.
This tutorial will guide you to create a documentation website using Github and Netlify using the MkDocs static site generator. Even though MkDocs is designed for documentation, it can be used to quickly create simple websites with a navigation menu. Since I’m on Windows, this tutorial is for users on Windows.
Let’s create a folder where our website project will be. I’ll call mine mkdocs at C:\Users\abdul\OneDrive\Documents\Websites\mkdocs.
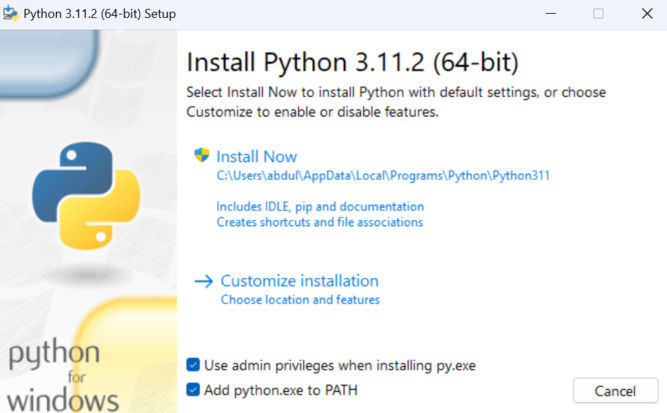
Install Python
If you don’t have Python installed, you’ll need to install it. Visit Python and download the executable. When installing, be sure to check the box to “Add python.exe to PATH” is checked.
Verify python was installed by running
python --version
You may need to close and reopen the command prompt for this to work.
Install pip
pip is a package manager for python. If you just installed python, then pip will likely be installed. Test this by running the following command
pip --version
I have pip version 22.3.1. This version may be out of date, so let’s update it with
python.exe -m pip install --upgrade pip
Now, when I run pip --version, I see a newer version installed.
Create a Virtual Environment
A python virtual environment is a tool that helps to keep dependencies required by different projects separate by creating isolated python virtual environments for them. This is one of the most important tools that most Python developers use. In a terminal, go to your project folder and run the following command. venv can be any name you want.
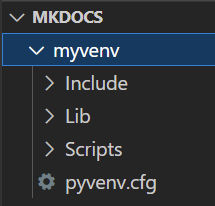
python -m venv myvenv
This creates a folder called myvenv in your project folder containing a bunch of folders and files.
Activate Virtual Environment
Now we need to activate our virtual environment. Remember: this must be done every time you begin working on your project. You’ll know you’ve activated the virtual environment if the command prompt prefix shows the name of your virtual environment.
Windows
On Windows, we have to activate it by moving into the virtual environment folder and running Scripts\Activate.
Notice how the command prompt prefix is now myvenv.
Linux/Mac
If you’re on Linux or Mac, use the following command from the project root folder.
source myvenv/bin/activate
where myvenv is whatever name you gave your virtual environment.
Install mkdocs-material theme
You can have different themes with mkdocs. The best theme is mkdocs-material so we’ll install that one. Go back to your project root folder and run the following command.
pip install mkdocs-material
This will download the mkdocs-material dependencies in myvenv\Lib\site-packages folder.
Create a New mkdocs Site
Now, let’s create a new mkdocs site by running the following command in our project root folder.
mkdocs new .
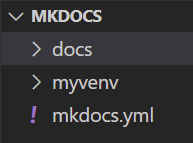
This will create 2 files.
mkdocs.yml is a configuration file.
index.md is a documentation page.
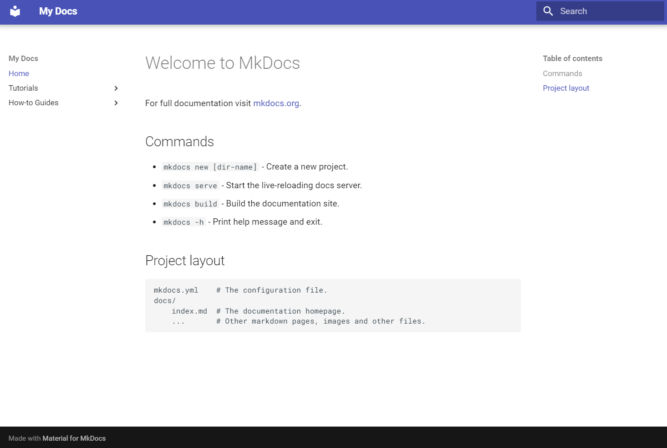
Preview the Site
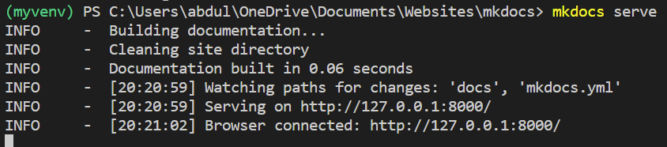
MkDocs comes with a built-in dev server that lets you preview your documentation as you work on it. Make sure you’re in the same directory as the mkdocs.yml configuration file, and then start the server by running the following command:
mkdocs serve
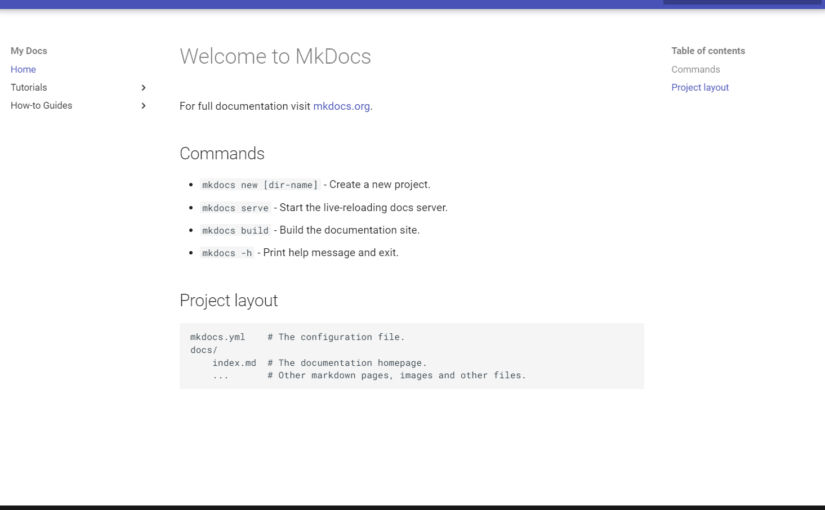
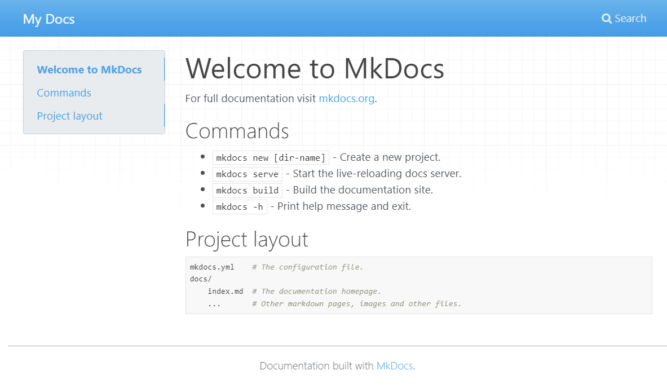
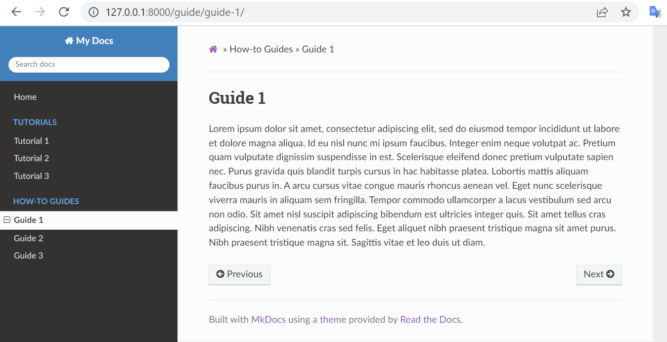
Now we have a dev server. If you open http://127.0.0.1:8000/ in a browser, you’ll see the index page.
Customize The Site
Open mkdocs.yaml to make the following changes.
Change Site Name
The default site name is “My Docs”. You can change it here.
site_name: My Docs
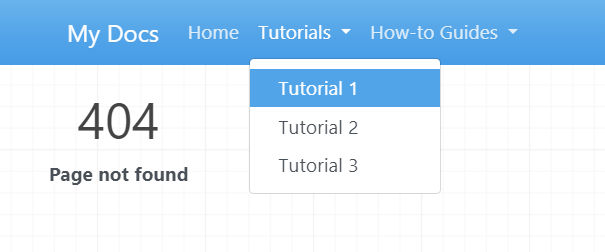
Add Pages to Site
Add an order, title, and nesting of each page in the navigation header by adding a nav setting. For example,
So far, we’ve been previewing the changes to the site. There are still only 2 files. Let’s build the site. In another terminal window, run the following command.
mkdocs build
This creates a site folder containing the built HTML files and other files.
Create Pages
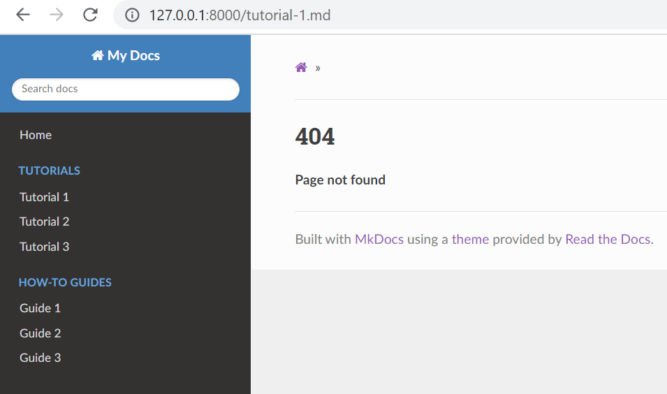
We have our nav menu, but we don’t have pages the nav links to. Let’s create those pages now. The file name and path should match what’s in the mkdocs.yaml config file and the source files should be in the docs folder. I just created some placeholder page content for demonstration purposes.
Now, our documentation website is starting to look good.
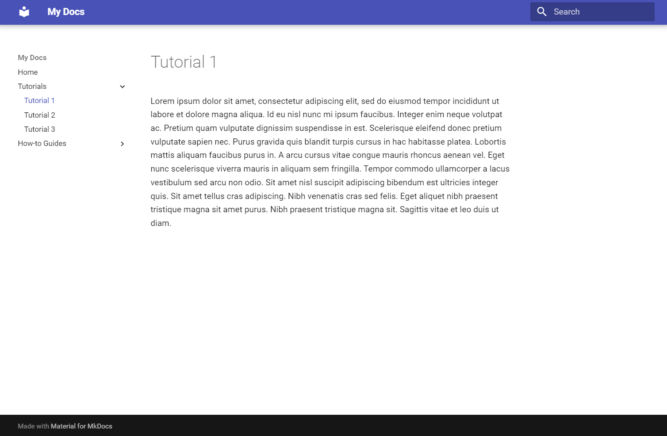
Change the Theme to the Material Theme
Let’s change the theme to the Material theme by updating the mkdocs.yaml file.
theme: name: material
When you do this, your dev server may crash. Just restart it with mkdocs serve. And just like that, our theme is now the Material theme.
Customize the Theme
You’ll notice that in your source code, there are no theme files. There are different ways you can customize the theme as described in the official manual. You can also create a new theme. Theme files use the Jinja2 templating engine.
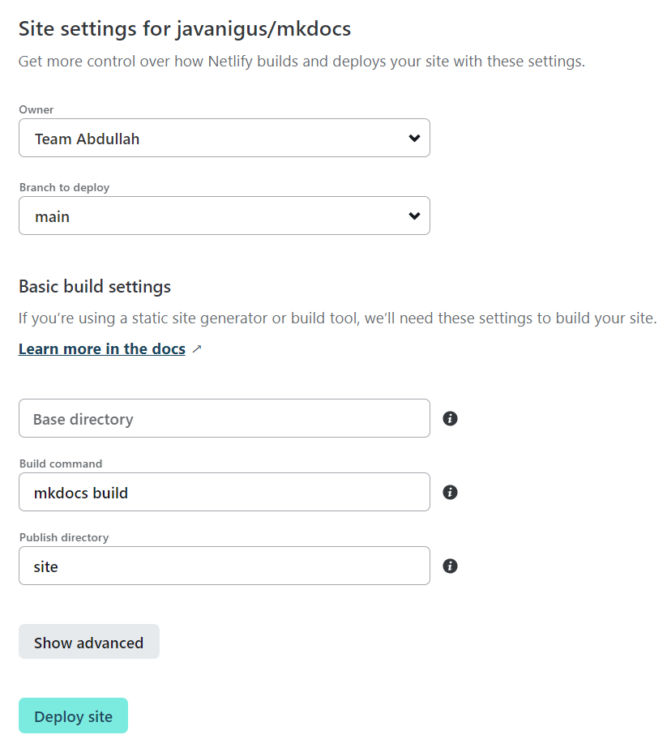
Deploy to Netlify
In order to deploy to Netlify, we need
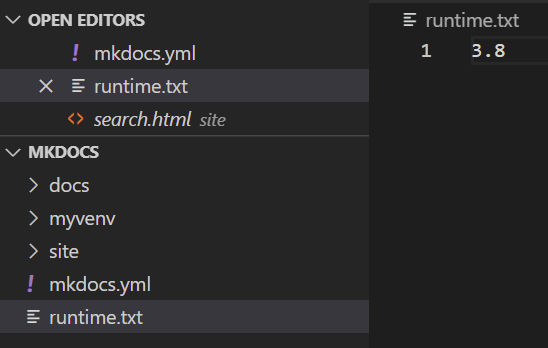
runtime.txt (a file that specifies the version of python to run)
requirements.txt
netlify.toml
GitHub account
Create runtime.txt
Create a file in the project root with the version of python you want Netlify to use when building the site. The current latest version of python that Netlify supports is 3.8. The version number must be x.y (major and minor versions only, no patch numbers).
Add requirements.txt
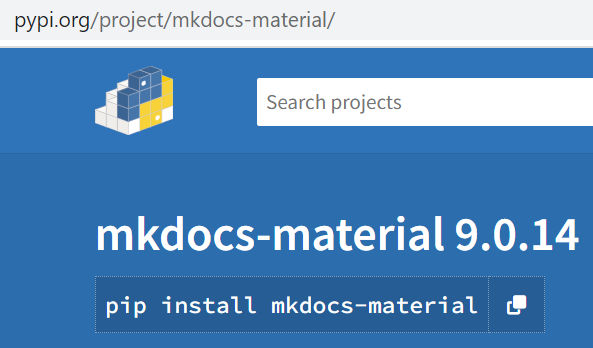
This file will list software dependencies and versions. Create a requirements.txt file with the following
mkdocs-material==9.0.14
You’ll end up with a requirements.txt file similar to this. 9.0.14 is the current version of mkdocs-material pip package at https://pypi.org/project/mkdocs-material/.
Create netlify.toml
netlify.toml is a Netlify configuration file. Create the file and add the following to it.
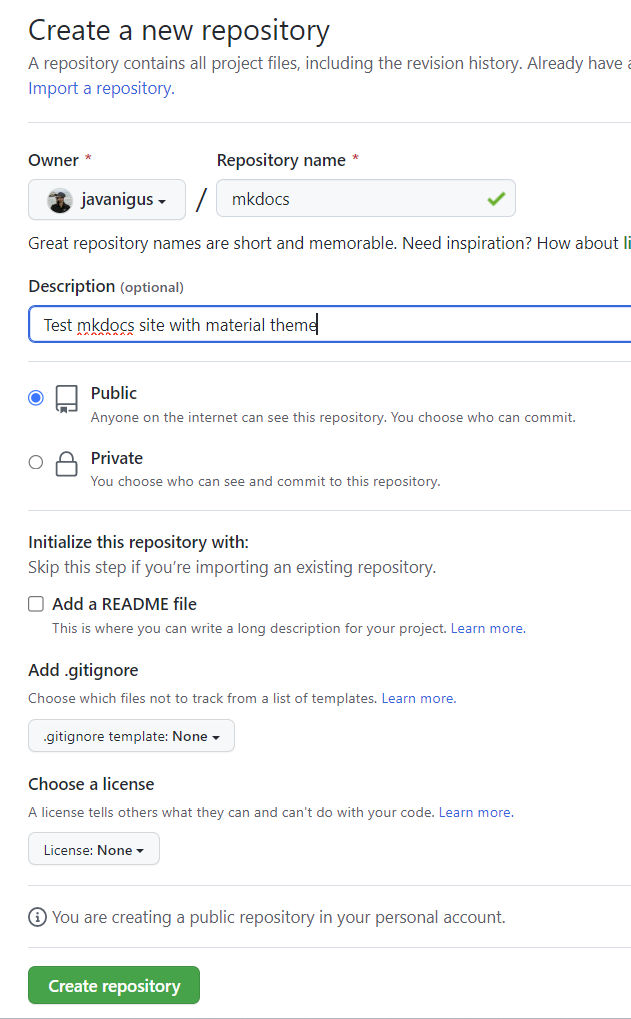
To avoid errors, do not initialize the new repository with README, license, or gitignore files. You can add these files after your project has been pushed to GitHub.
Initialize the local directory as a git repo. If you don’t have git installed, you’ll need to install it first.
Run git init -b main in our project folder. This will create a hidden .git folder.
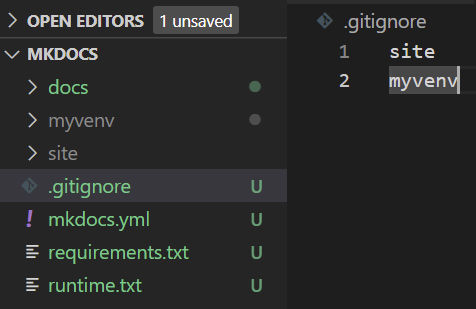
Create a .gitignore file with the following entries to ignore them from being tracked by git.
site
myvenv
Add the files in your new local repository. This stages them for the first commit.
git add .
Commit the files that you’ve staged in your local repository.
git commit -m "First commit"
At the top of your repository on GitHub.com’s Quick Setup page, click to copy the remote repository URL.
One of the food options I like the most at Chipotle is their beef barbacoa. Chipotle doesn’t tell you their recipe, but they do tell you the ingredients. Here’s a beef barbacoa recipe that tastes almost as good as the one at Chipotle and is super easy to make.
This recipe involves using a slow cooker.
Ingredients
3 lb Beef brisket or chuck roast (trimmed and cut into 2-inch chunks. Remove most of the fat.)
1 cup Beef broth (or chicken broth)
2 medium Goya Foods Chipotle Peppers in Adobo Sauce (including the sauce, about 4 tsp)
5 cloves Garlic (minced)
1 tbsp Dried oregano
2 tsp Cumin
1 tsp Sea salt
1 tsp Black pepper
2 whole Bay leaf
1/2 tsp Ground cloves
2 tbsp Apple cider vinegar (optional)
2 tbsp Lime juice (optional)
Instructions
Combine the broth, chipotle chiles in adobo sauce, garlic, apple cider vinegar, lime juice, dried oregano, cumin, sea salt, black pepper, and ground cloves in a blender (everything except the beef and bay leaves). Puree until smooth.
Place the beef chunks in the slow cooker. Pour the pureed mixture from the blender on top. Add the (whole) bay leaves.
Cook for 4-6 hours on high or 8-10 hours on low, until the beef is fall-apart tender.
Remove the bay leaves. Shred the meat using two forks and stir into the juices. Cover and rest for 5-10 minutes to allow the beef to absorb even more flavor. Use a slotted spoon to serve.
Beef chuck short ribs at Costco – $15.99 / lbBeef chuck steak boneless carne asada at Costco – $7.49 / lbBeef barbacoa over riced cauliflower
Svelte is similar to React and Vue, but instead of doing most of the work in the browser, Svelte does it in a compile step. Also, Svelte doesn’t do virtual DOM diffing or require HTML/CSS within JavaScript. Here’s a video showing code to create a simple to-do list app using 10 different JavaScript frameworks. Personally, I find the Svelte code to be the simplest and most elegant.
UPDATE: You can quickly set up preconfigured web stacks using Amazon Lightsail.
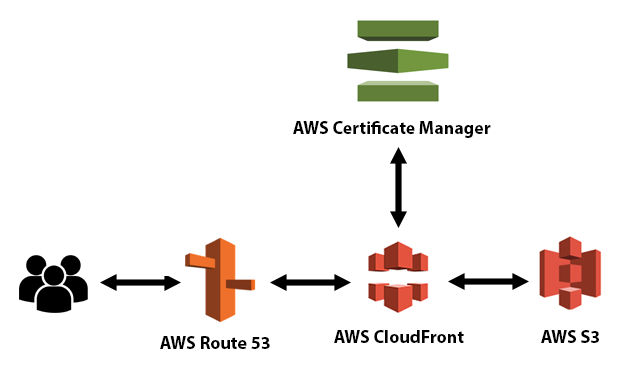
This tutorial will show you how to host a website on Amazon S3, Amazon CloudFront, and Amazon Route 53 using SSL and a custom domain.
Amazon S3 Amazon S3 is an object storage service. Files are objects.
Amazon CloudFront Amazon CloudFront is a content delivery network (CDN) service.
Amazon Route 53 Amazon Route 53 is a Domain Name System (DNS) web service. Route 53 connects user requests to internet applications running on AWS or on-premises.
AWS Certificate Manager AWS Certificate Manager (ACM) is used to provision, manage, and deploy public and private SSL/TLS certificates for use with AWS services and your internal connected resources. ACM removes the time-consuming manual process of purchasing, uploading, and renewing SSL/TLS certificates.
Create an S3 bucket
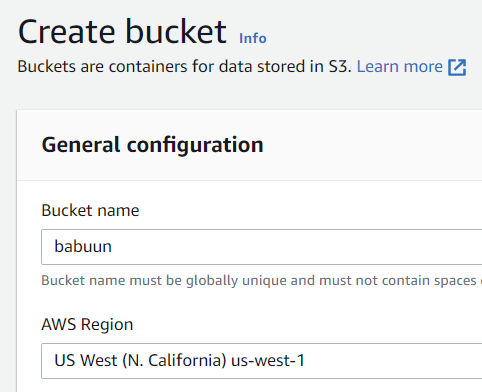
Go to your AWS console and search for S3. Click it.
Click ‘Create Bucket’. Choose a globally unique bucket name and AWS region.
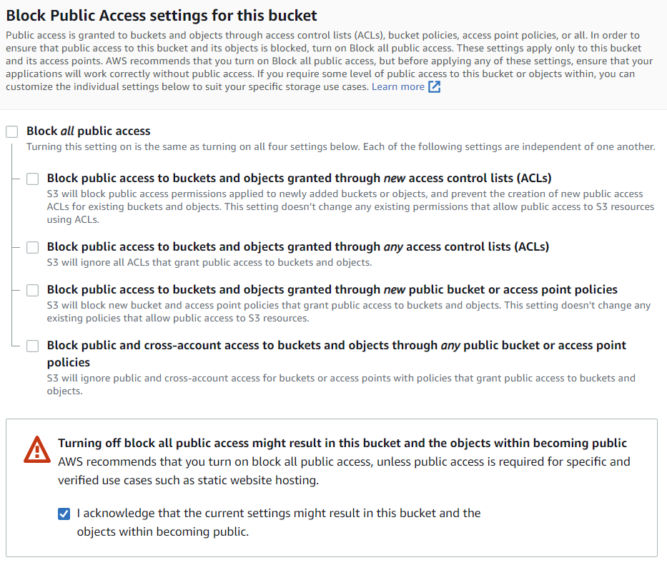
Untick “Block all public access” and confirm it, since we want our static website accessible from the internet.
Leave everything else as is and click ‘Create bucket’.
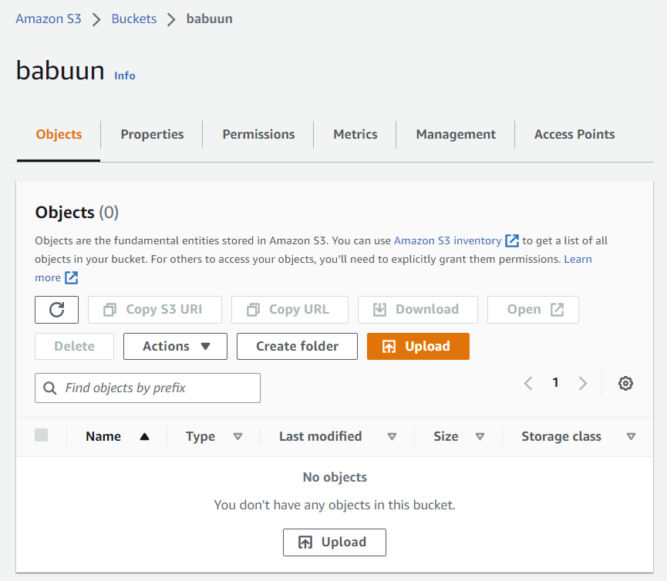
Open the bucket you just created from the console. The bucket should be empty.
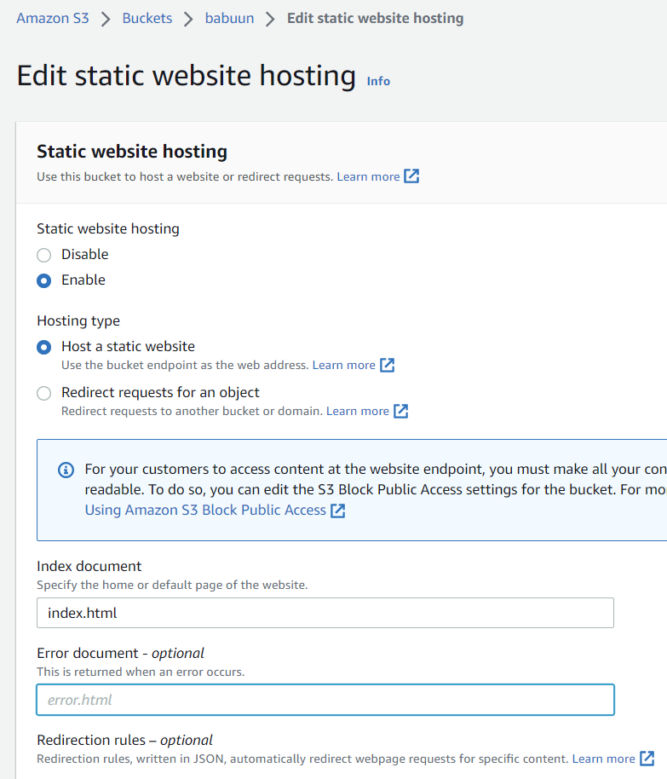
Click the Properties tab, and then sroll down to Static website hosting and click ‘Edit’.
Choose ‘Enable’ under “Static website hosting”
Choose “Host a static website”.
Choose an Index document. You can fill in “index.html”.
Hit Save changes.
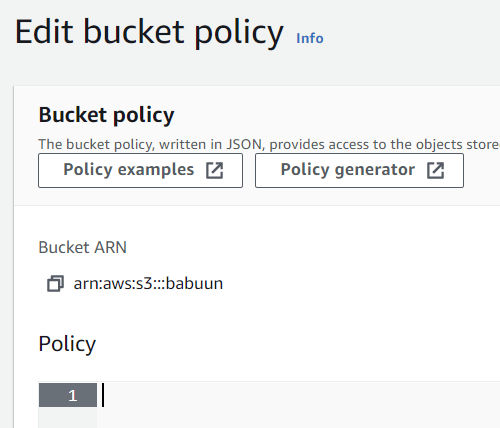
In S3, click the Permissions tab. Then Bucket Policy.
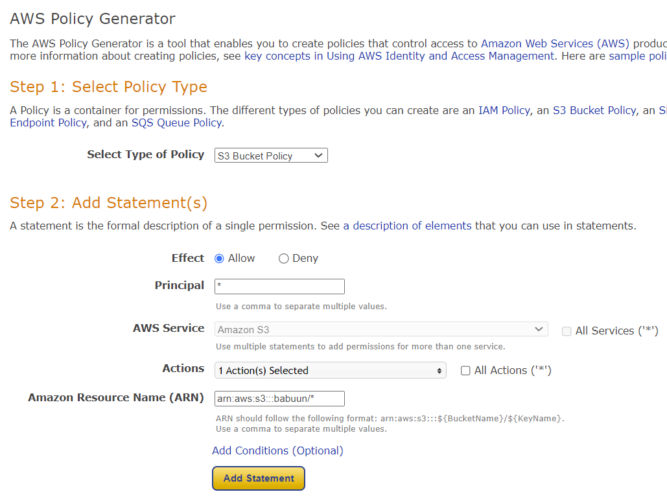
Here you need to fill in a policy that will allow the bucket to be publicly accessed. Open the official AWS policy generator at AWS Policy Generator in a new tab and generate a policy.
At the generator, choose S3 bucket policy as the Type of Policy. Principal will be an asterisk “*” (without quotes), and Actions will be “GetObject”.
Fill in your ARN. It can be found in AWS Console where you were about to fill in the bucket policy. There, at the top of the page, you should be able to find the ARN in the format of arn:aws:s3:::<bucket_name>.
Important: before you paste in the ARN, append a slash and asterisk at the end, so it will look something like: arn:aws:s3:::babuun/* (my bucket name is “babuun”). This will allow access to everything inside the bucket.
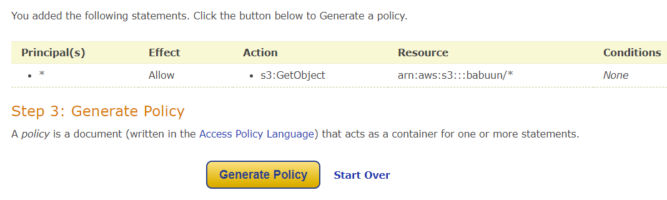
Click Add Statement and then Generate policy.
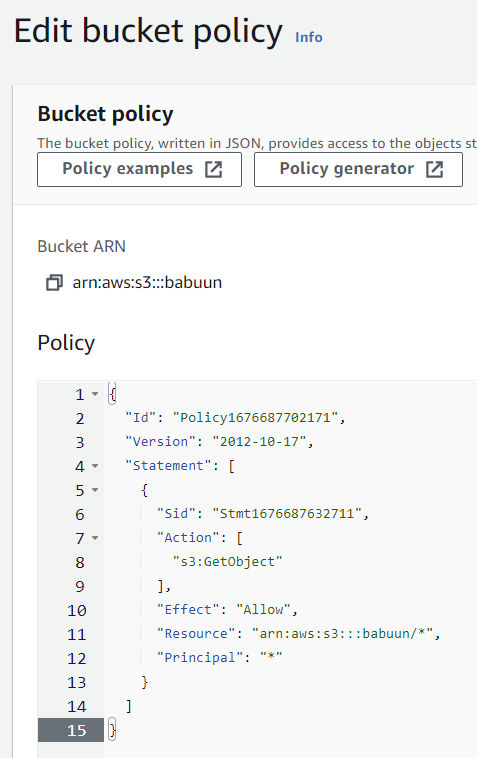
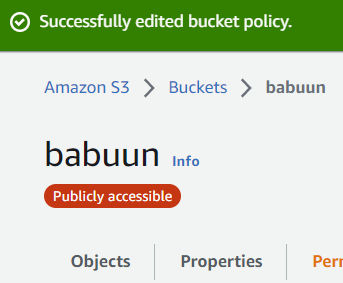
Copy the whole policy over to the S3 AWS console in the Edit bucket policy page and click Save Changes.
Now, when you open your bucket, you should see a red bubble with white text Publicly accessible under the name of your bucket. If you do, everything is correct and we can proceed.
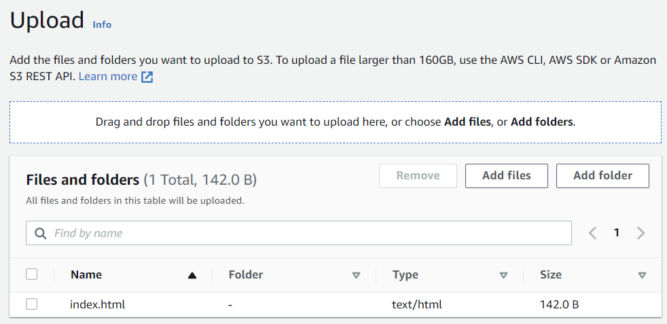
In your AWS console inside your S3 Bucket hit Upload, then Add files and upload your website. If you don’t have one yet, just create an index.html file with the following content and upload it. You can also create a folder, e.g. for images.
In your AWS Console search for Route 53 under Services.
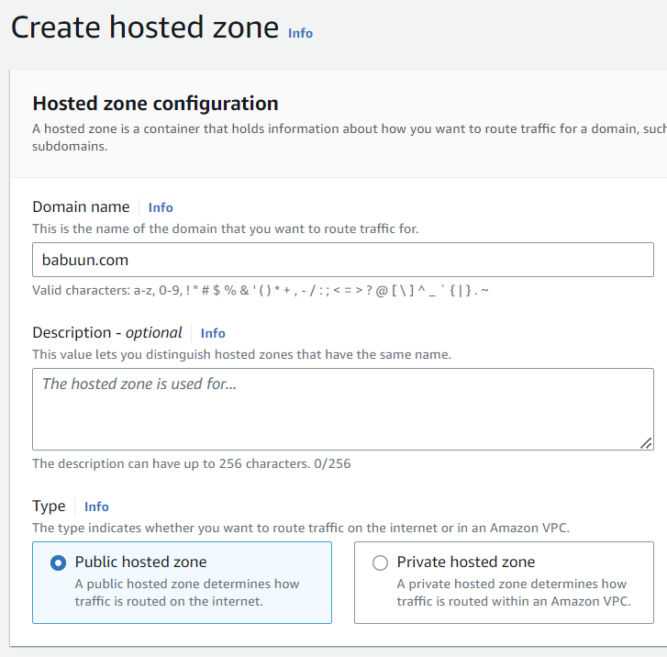
Under ‘DNS management’, click Create hosted zone.
Inside the ‘Domain name’ field, input your domain name. You can get one from any domain registrar like GoDaddy.
‘Type’ will be Public hosted zone.
Click Create hosted zone.
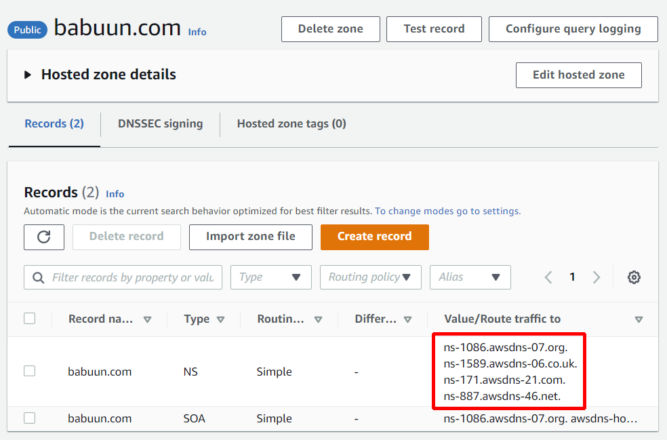
Now we need to link our domain with the records in Route 53. For the zone we just created, you’ll see 2 types of records. The first on is “NS”, which stands for “name server”. There are 4 name servers in this record.
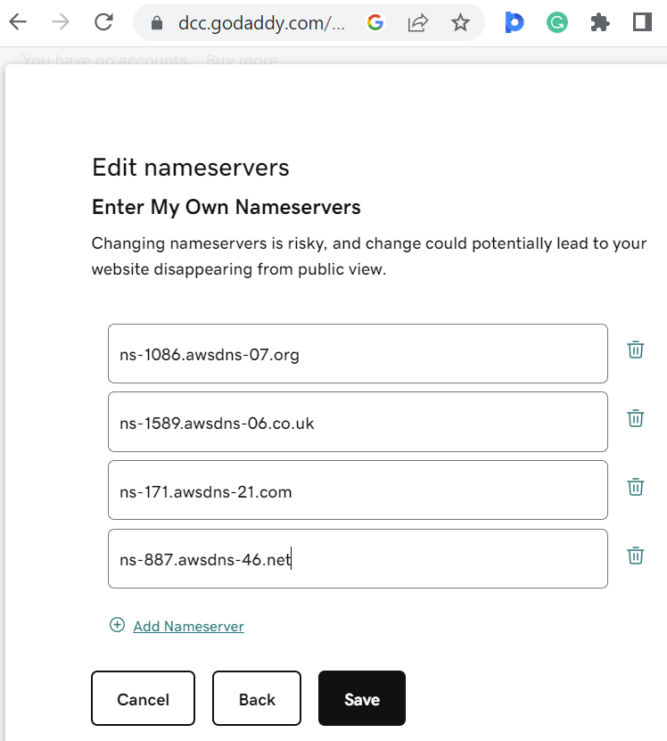
Open a new browser tab and go to your domain’s DNS management page. There, you’ll see a section to update nameservers. My domain is babuun.com and I registered it with GoDaddy. Copy the name server values in Route 53 to your DNS management page. Make sure to remove the dot at the end. In doing so, when someone tries to reach your domain, you redirect them to one of these name servers. Save your nameserver changes. Keep this browser tab open as you’ll need it in the next section.
Set up a certificate
In your AWS Console, search for Certificate Manager and click the link.
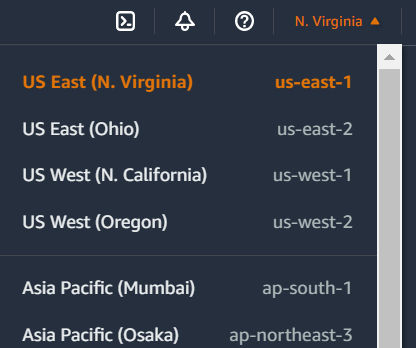
IMPORTANT: In the region dropdown, choose “US East (N. Virginia)”.
Click “Request Certificate” > “Request a Public Certificate”.
Fill in the domain name. In my case, it’s “babuun.com”.
For “Validation Method”, use the recommended value (DNS Validation).
Leave everything else as is and click the Request button.
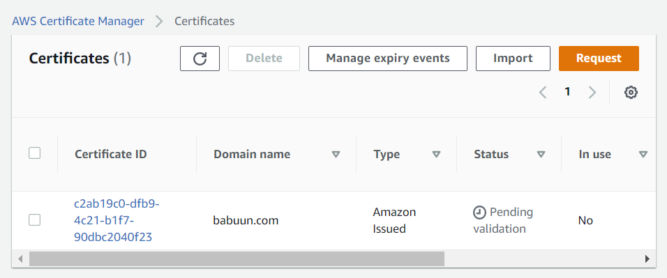
On the next screen, you’ll see the certificate is “pending validation”. In order to validate it, we need to link it to our Route 53 records. Click on the link under “Certificate ID”.
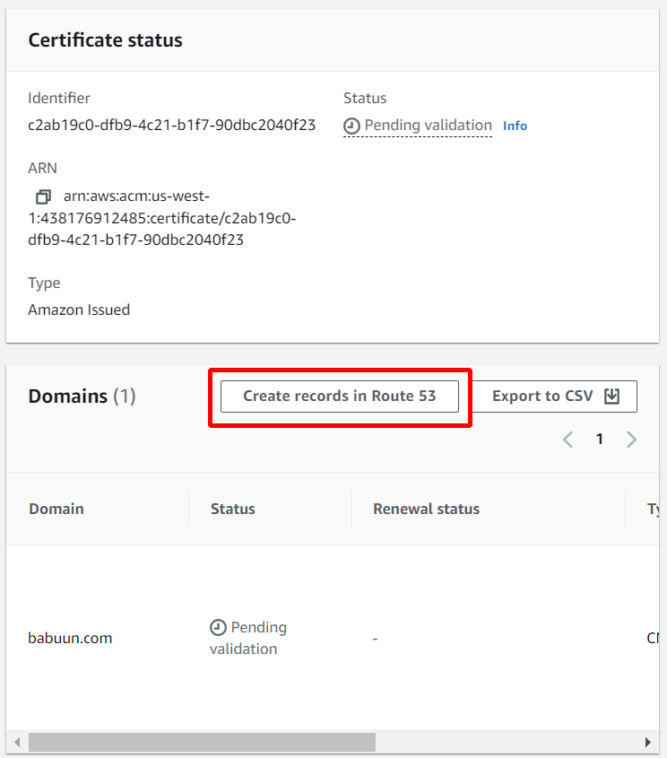
Click on “Create records in Route 53”.
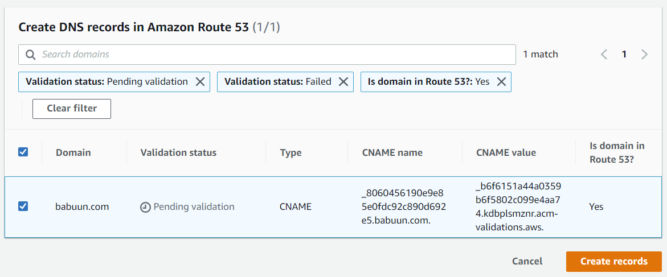
Then, click the “Create records” button.
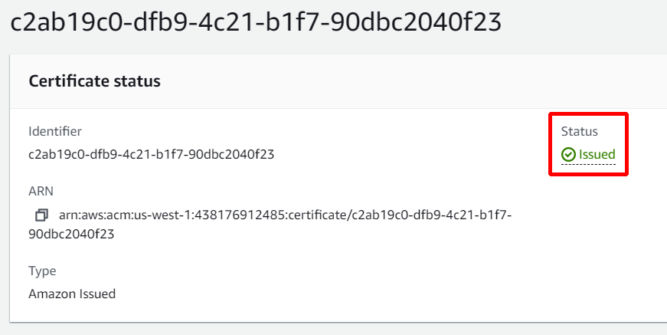
Wait up to 30 minutes for the certificate to be issued. The status will change from “Pending validation” to “Issued”.
Set up a CloudFront distribution
We will create a CloudFront distribution that is connected to our S3 bucket. When anyone tries to access our distribution, they will actually be accessing our S3 bucket while taking advantage of the speed of CloudFront.
In your AWS Console search for CloudFront and click the link.
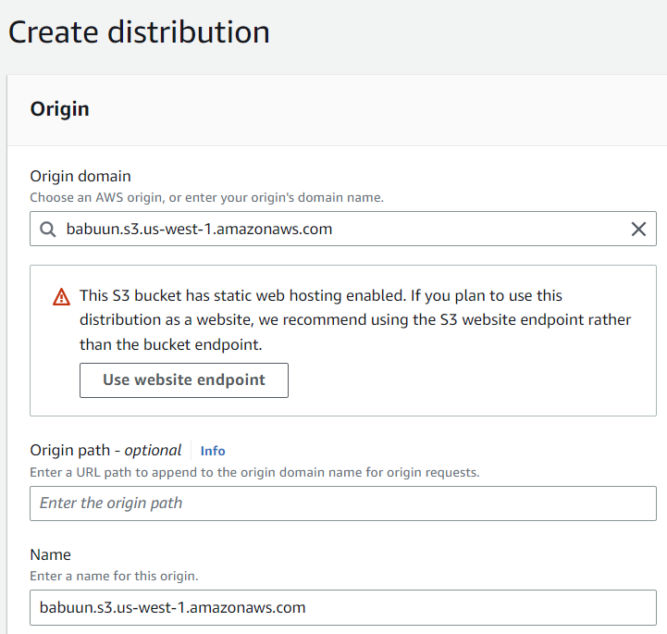
Click Create Distribution. On the next page, under “Origin domain”, select the S3 bucket we created earlier.
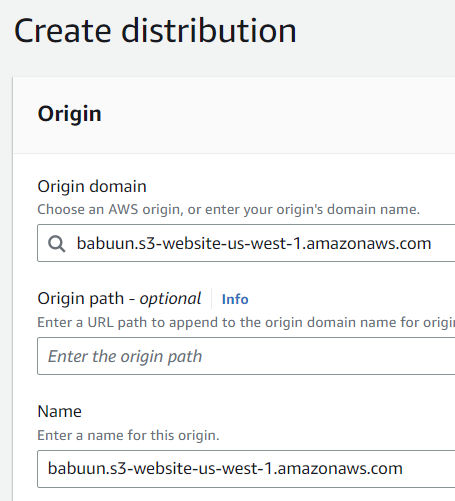
CloudFront will notice that the bucket was set up to host a website. Click the “Use website endpoint” button. CloudFront will automatically update the values for you.
Under Viewer Protocol Policy choose Redirect HTTP to HTTPS
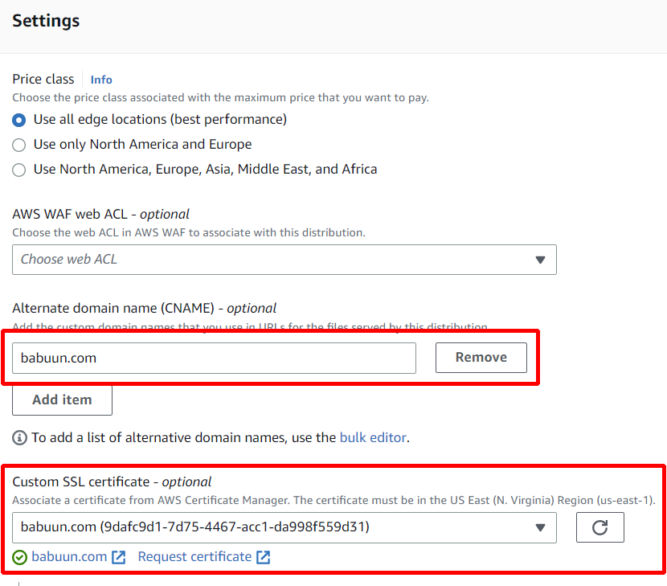
Under “Alternate Domain Names (CNAMEs)”, enter your domain name, e.g. babuun.com.
Under “Custom SSL certificate”, choose the certificate we created earlier. If it’s not available, the certificate may not have been issued yet. Wait 30 minutes or so and click the refresh button until you see the certificate. Select the certificate.
Click Create Distribution at the very bottom of the page.
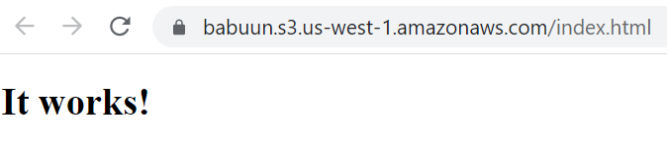
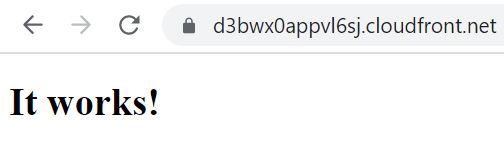
The distribution takes about 10-20 minutes to provision. Once it is provisioned (Status = Enabled, Last modified = a date), you can test it by pasting the URL into your browser. You should see the website you uploaded into S3.
However, your custom domain won’t load in a browser yet. To fix that, we need to create a record in Route 53.
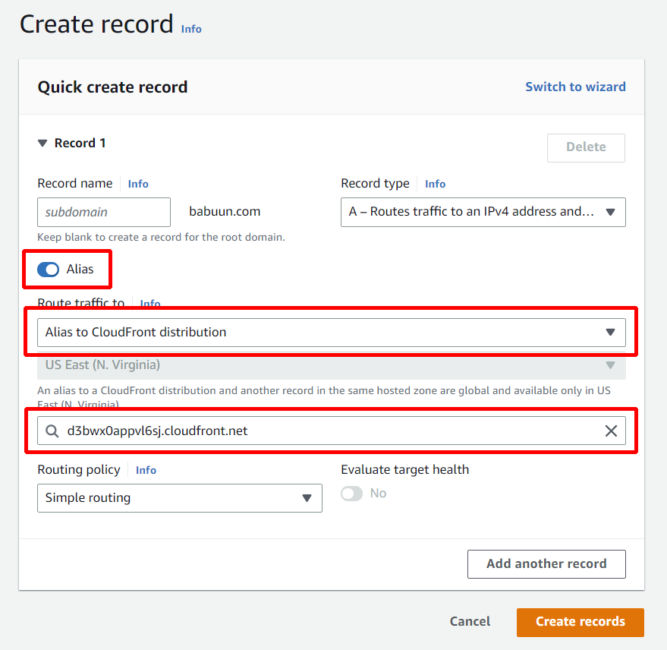
Set up a record in Route 53
Go back to Route 53 and click on your domain.
Click Create record.
Click Alias.
Click the dropdown menu at Value/Route traffic to and choose Alias to CloudFront distribution.
Choose the distribution you provisioned previously.
Notice that the only available region is US East (N. Virginia)[us-east-1]. This is due to the fact that we provisioned an SSL Certificate via AWS Certificate manager. This service is only available in US East 1.
Now, just wait a few minutes for the DNS records to update and try to load your domain name. If everything went correctly, you should see your static website distributed via CloudFront.
And there it is…
Alternate Domain (CNAME)
The instructions above involve using Route 53 as the DNS manager for the domain by updating the nameservers for the domain at the domain registrar to point to AWS’ nameservers. By having Route 53 manage the DNS records, you can have the root domain (babuun.com) point to AWS CloudFront and you can add a CNAME (alternate name) such as www.babuun.com point to AWS CloudFront as well. So, your website would be accessible at both https://babuun.com and https://www.babuun.com.
If you don’t want to use AWS Route 53 as your DNS manager, you would only be able to create a CNAME in your external DNS manager that points to your CloudFront URL as shown below.
In this example, I made www.babuun.com point to d3bwx0appvl6sj.cloudfront.net in GoDaddy.com’s DNS manager. You can’t have the root domain (babuun.com) point to CloudFront because the root domain destination can only be set in the A record, which must point to an IP address, not a domain. Since we don’t know the IP address of CloudFront, then babuun.com will not point to CloudFront. As a workaround, you could have the root domain point to an IP address of a server you have access to, and then add a redirect from there to www.babuun.com.
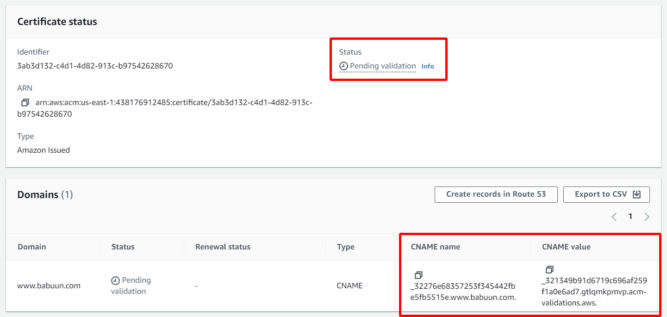
Since you’ll need a certificate specifically for www.babuun.com, or use a wildcard cert like *.babuun.com, you need to create a new certificate in ACM. The instructions are the same as above. After requesting a new certificate, you’ll see the status is “Pending validation”. Since you chose DNS validation, you’ll need to create a new CNAME record in your external registrar with the CNAME name and value provided.
The screenshot below shows the relevant records in my DNS manager on GoDaddy.
ACM will take up to 30 minutes to verify the changes after which time the certificate’s status will change to “Issued.
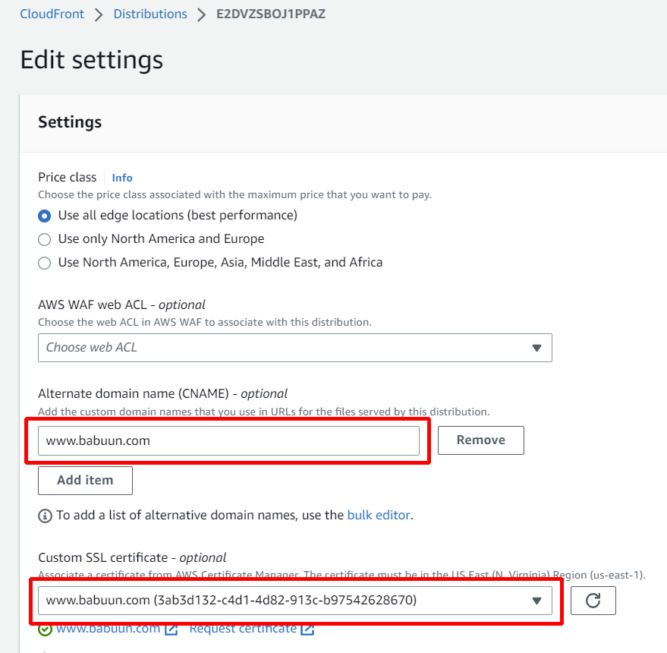
Now that the certificate is issued, you can update the CloudFront distribution settings by adding the newly issued certificate.
If you are using AWS CloudFront only for static assets, e.g. PDFs and images, then it makes sense to just create a CNAME record with an alternate name like “cdn.babuun.com” or “static.babuun.com” or “assets.babuun.com”.
Bucket Versioning
Versioning is a means of keeping multiple variants of an object in the same bucket. You can use versioning to preserve, retrieve, and restore every version of every object stored in your Amazon S3 bucket. With versioning, you can easily recover from both unintended user actions and application failures.
In S3, choose your bucket, then click the Properties tab, then enable bucket versioning.
I just finished reading the book No Rules Rules: Netflix and the Culture of Reinvention by Reed Hastings, co-founder and former CEO of Netflix, and Erin Meyer. It’s an extremely popular book, based on its ratings. Since I didn’t have time to read the full 320-page book, I read the 7-page summary on Blinkist. I can see why so many people like it. This book is most definitely required reading for anyone managing teams in a company. In fact, the higher you are in the org chart, the more you should read this book!
As everyone probably knows, Netflix is the wildly successful online film streaming service where people can watch movies, documentaries, TV series, and more. Its success can be attributed to many things including its ability to nimbly pivot. It started as a DVD-by-mail subscription service, then transitioned to an online streaming service. It then began licensing original content produced by other studios, and finally, it started producing its own in-house movies and TV shows. In the beginning, it was 1000 times smaller than brick-and-mortar video rental store Blockbuster yet managed to put Blockbuster out of business some 10 years later. Netflix grew 300 times faster than the NASDAQ stock index over 17 years, and a 2018 survey rated it the top place to work in Silicon Valley.
Here are the key takeaways from the book.
1: High talent density encourages employees to perform at their very best
Companies should focus on hiring and retaining highly talented people. To do so, they need to pay rock-star salaries. High performers thrive in an environment with other high performers, and this environment attracts other high performers and holds people to a higher standard. When everyone is excellent, performance skyrockets.
2. Radical candor helps Netflix employees improve, even if it can be difficult to hear
Radical candor is a vital part of Netflix’s company culture. It’s perfectly normal for people to directly contradict their bosses in meetings if they disagree with something. In fact, employees are expected to disagree. If you don’t, it’s as if you are purposely being disloyal to the company. You could help the business improve, but you’re choosing not to.
Unlike at most companies, where there’s just one annual performance review that is top-down, at Netflix, employees are encouraged to give feedback at all times. And, more importantly, they are encouraged to give feedback to their bosses, even more so than the other way around. This is very unconventional, but it actually makes a lot of sense, because the higher you are in an organization, the more likely you are to make a mistake that seriously impacts the company.
There are 4 rules to candor to make it effective:
give feedback with the aim of helping.
your feedback should be actionable.
when receiving feedback, you should appreciate the effort and bravery of your colleague in speaking up.
you should think carefully about whether or not to accept it.
3. Getting rid of useless policies made Netflix employees more accountable
Micromanaging is a waste of people’s time as is requiring employees to follow useless policies. Giving employees more freedom promotes accountability. It signals that you trust them.
4. Maintaining a talent-dense team requires a lot of intense effort.
A lot of companies talk about how their employees are a family. I’d often read new employee introduction emails where they’d say they’re excited to join the company’s family. At Netflix, they don’t consider their talent-dense team like family because they don’t believe that a particular job is something you should have for life regardless of your performance. Instead, they believe a job is something you do for a particular period of time when you’re the best person for that job and the job is the best position for you. Netflix employees are more like a professional sports team of highly talented people rather than a family of people with varying degrees of talent.
To maintain talent density, you have to do something unpleasant: fire people who are merely adequate. To minimize having to do this, it makes sense to put more effort into testing and interviewing candidates. Since firing people can’t impact their personal finances and morale, Netflix offers generous severance packages. An individual contributor gets four months’ pay, and a VP gets nine months.
5. At talent-dense organizations, dispersed decision-making is most efficient.
At most companies, the boss is there to either approve or shut down employees’ ideas. That’s leadership with control. This is a great way to limit innovation and slow down growth.
At Netflix, managers lead with context, letting employees use their own judgment to make the choice they feel is best for the company. With employees making their own decisions, senior leadership is freed up for other things.
I’ve worked with people at all levels of an organization and have seen people make costly, long-lasting mistakes. After a while, it’s hard to not notice a pattern, especially when some of the mistakes affect you. If you stop to think about these mistakes and their root cause, you’ll realize that they could have easily been avoided by following common sense and business best practices. Following are some of the common mistakes I’ve seen that have the potential to have costly, long-term detrimental effects.
Poor Hiring
Successful business leaders and venture capitalists (VCs) know this all too well. What makes or breaks a company is its people, especially the management team. Sadly, I’ve seen many people, including high-ranking executives, make obvious mistakes when interviewing candidates and hiring people. Some of these mistakes include:
Hiring a full-time employee without having a full-time amount of work for them
Asking completely irrelevant, high-ranking employees to interview a candidate
Not having certain employees interview a candidate who they’ll have to work very closely with just because they are low-ranking employees
Judging a candidate based solely on their resume and a short, verbal interview
Writing vague job descriptions and not setting correct expectations up front
Not testing a candidate
Some examples are
Having a director of public relations instead of a web developer interview a web designer candidate
Not having a web developer interview a director of content, even though they’d be working together on a daily basis
Not testing a copywriter or proofreader to write an essay or proofread a blog post
Hiring a director of content marketing to own content but not confirm their ability and interest in performing certain content-related tasks, e.g. writing and proofreading content.
Personal experience being interviewed
When I’ve interviewed at some companies, sometimes I’d be tested. I’ve had to write some code at home and sometimes I’ve had to answer a series of technical questions in real time. I’ve even had to give a presentation in front of a group of 10 or 15 people and write code on a whiteboard. As much as I didn’t like doing this, it made sense for the company to request it.
Testing candidates
When I posted a job ad to hire a web developer in India, I was inundated with applications. Since hiring a skilled and competent employee will make my life easier and make me look good, I spent extra time finding the best candidate available. I first shortlisted the resumes and then ranked each one based on their resume. My recruiter set up meetings with each one in order of ranking. I wrote a series of technical and non-technical questions to ask each candidate. That made the interview process very structured and methodical. It also was fair and made it easy for me to compare each candidate. Based on their verbal answers, I shortlisted them and gave a take-home coding test to the top 3. Each candidate was given 3 or so days to complete the test. Before reviewing each test, my impression was that all candidates were more or less equal in skill. After reviewing their tests, the first candidate failed horribly. The second candidate wrote overly complicated code and made some obvious mistakes. The third candidate wrote simple, clear code and only had very minor mistakes. I hired the third candidate and haven’t regretted doing so ever since. This experience goes to show that a candidate may look good on paper, but fail miserably in practice.
Reviewing sample work
In another situation, I needed to hire a proofreader to review various kinds of content, including product pages, blog posts, emails, etc. I didn’t need a full-time person, so I sought a freelancer on a pay-per-project basis. A seasoned writer was referred to me. When I saw her sample articles, each one contained some obvious typos. This was a red flag since a simple spell checker would have caught them. I did not bother to proceed with the referral. On another occasion, a resume was forwarded to me. Ironically, the candidate’s resume itself was full of typos, so there was no point in proceeding with that candidate either. Surprisingly, hiring managers don’t always look at these signs and are just overly optimistic and hopeful that the candidates will just perform well.
Not all candidates can be tested or may have a portfolio of sample work, but with some creativity, you can probably find a way to gauge their abilities to meet your needs and expectations to fill a particular job besides just looking at their resume and interviewing them.
Unvalidated Decision-Making
Every now and then, I come across some employee who makes a decision based on tradition or assumptions rather than data or subject-matter-expert consultation. It requires no explanation why the latter is better. Here are some examples.
Not making decisions based on data
Someone wants to update the top-level navigation of a website to include a link to their department’s website, e.g. training, support, documentation, blog, videos, etc. They know that their department’s website is accessible from the 2nd-level navigation and from many other places on the website. However, they insist on being at the top level. They don’t bother to ask for website page traffic data to see how many people even visit their section of the website to justify their change request. According to a year’s worth of Google Analytics data, it turns out that only a small fraction of people visit their website. In this case, putting a link to their website at the top-level navigation would not be a smart decision.
Not asking subject matter experts
An executive hears from the website manager that the website is custom-coded by a handful of web developers. Sometime later, the executive hears complaints from marketing campaign stakeholders that it takes too long to create website landing pages. He assumes that the delays are because the pages are custom-coded. He becomes obsessed with migrating the website to a content management system (CMS). He sees an ad for a CMS that claims it can make website updates a breeze. He then embarks on an expensive project to migrate the website to a CMS without realizing that the root cause of the delays had nothing to do with how the pages were built. Had the executive asked the subject matter experts (in this case, the website manager), he would have learned that the delays were caused by the backend integration with other systems, e.g. Marketo and Salesforce, and by the time difference between teams in different countries. In this case, the executive made a bad decision based on assumption, even though the answer to his concerns was a simple email or phone call away.
Quantity Over Quality
Most of the time, quality is more effective than quantity. For example, you can publish many poorly written blog posts and landing pages that get no views, or you can publish a few strategically written ones that go viral. Another example is creating a bunch of paid social marketing campaigns with plain graphics and rushed messaging only to realize that you’re wasting development time and throwing ad dollars away because all of the campaigns are of low quality and therefore ineffective.
Unless you’re a Nigerian scammer who mass emails people all over the world promising high investment returns, you should probably focus on quality over quantity.
Listening Only to Higher-Ranking Employees
Another mistake that some executives make is listening only to high-ranking employees as if one’s rank within an organization automatically makes them more knowledgeable about all matters in and outside their particular area of expertise.
For example, instead of asking a junior web developer, a senior director of public relations may be asked if she approves the hiring of a graphic and web design candidate. While it is true that website graphics are usually public in nature and therefore, a public relations specialist may seem relevant, their relevance is so tangential that it is insignificant. On the other hand, a lower-ranking web developer would be more relevant to approve or disapprove of the candidate since the web developer would have to work closely with the candidate almost daily.
In another example, an executive might consult a chief technology offer or chief information officer instead of a website manager about rearchitecting a website. That’s like consulting a chief medical officer instead of an eye doctor about blurry vision. The fact of the matter is the higher one’s rank, the less specialized they are in specific issues because they are too busy being concerned about high-level issues or with issues spanning many different areas. Just as no doctor can specialize in all areas of health, no one can specialize in all areas of technology or some other vast field.
Executives may assume that if a high-ranking employee can’t provide answers with confidence, then the high-ranking employee can consult the next lower-ranking employee down the chain until someone is knowledgeable enough to provide good answers. This approach may work, depending on the size and situation of your organization, but it is often unnecessary and just wastes people’s time as the information flow may have to pass through multiple layers up and down an org chart instead of just going directly to the source, not to mention the potential of information to change as it passes through many people.
Unclear Job Responsibilities & Expectations
One thing I’ve noticed all too often is not knowing what people’s job responsibilities are and what we can expect from them. For example, there could be a director of content marketing as the primary point of contact for all matters related to content. When interviewing the person, it was not made clear what types of work they’d need to be responsible for. The assumption was that the director of content marketing just “owned” content. After hiring the individual, it became clear that he wanted to “own” as much as possible without actually doing as much as possible. One expectation of this employee was that he’d review content and approve it for publication. “Review” in this case can mean many things. It could mean to review the high-level messaging. It could mean to review and fix typos. It can also mean both and anything else related to content. This is where problems occur. Clear responsibilities and expectations were not set in the job description and after hiring. As a result, the employee became unhappy, employees who had to work with him became unhappy, and the employer wasted time and money.
Some employers will intentionally make a job description vague so that it could be interpreted in many different ways so the employer could tell the employee that some new task is part of their responsibility. This is a bad approach that will likely backfire. Tricking an employee to do something they didn’t expect to have to do will result in resentment and “quiet-quitting”, the act of doing the least amount of work just to not get fired. Unhappy employees become unmotivated to excel which would affect company performance.
I once interviewed a candidate for a director of content marketing position. I interviewed the candidate for almost 2 hours. I gave her as many examples as I could of the type of work she’d be responsible for and told her straight up that if she wasn’t interested in being responsible for certain tasks, then she was probably not a good fit. She said she was fine with everything, but she eventually didn’t get hired. Nevertheless, it’s better to be specific, thorough, and set clear expectations up front rather than have regrets later on.
Another example is in defining the job responsibilities of a director of brand and creative. Different people have different interpretations of what brand and creative entails. Some interpretations are
ensuring a company’s logo is used properly
creating print and/or web graphics
design user interfaces
owning all aspects of “creative” which includes both text and graphics content
being a hands-on contributor or just directing other people to be hands-on
The sky’s the limit when it comes to the various ways you can interpret what a director of brand and creative should be responsible for and what they should actually do. If the expectation is that they should not be hands-on yet he should own all graphics, then the company should expect to hire more people who will be hands-on graphics editors.
Without clear, upfront expectations, there’s bound to be disappointment and regret from both parties. Rather than waste everyone’s time and the company’s money, it’s better to be as clear as possible before giving someone a job offer.